Housing Market Visualization (1979-2017)
Objective
The objective of this notebook is to create a time-lapse visualization of the dynamic relationship between median home value, as measured by regional ZHVI, and regional median household income from 1979 to 2017. ZHVI is a home value index created by Zillow which is the median of all estimated home values for a given region within a given quarter. The dataset used in this notebook contains ZHVI values for 916 metropolitan regions within the US sampled quarterly from March of 1979 to June of 2017. For each quarter, regional ZHVI values are plotted against regional median household incomes and chronologically strung together into frame of a resulting gif.
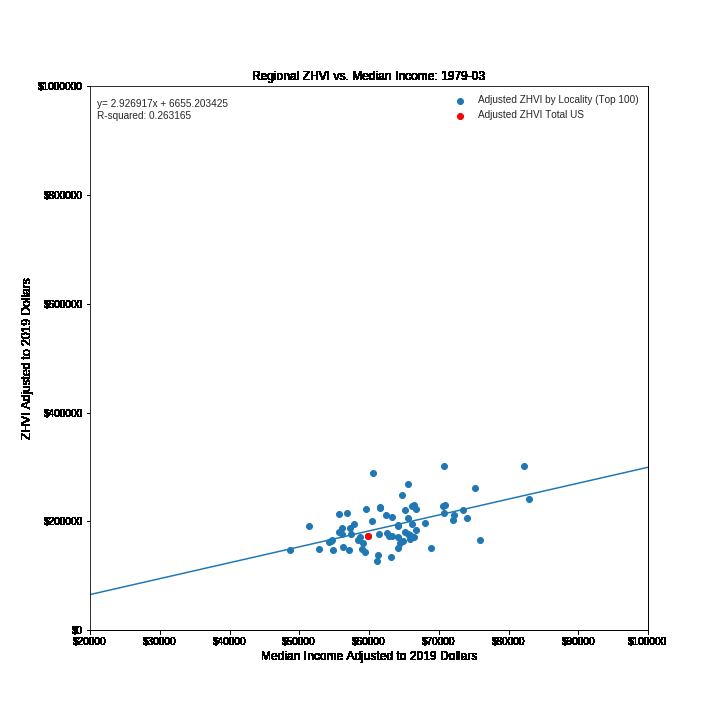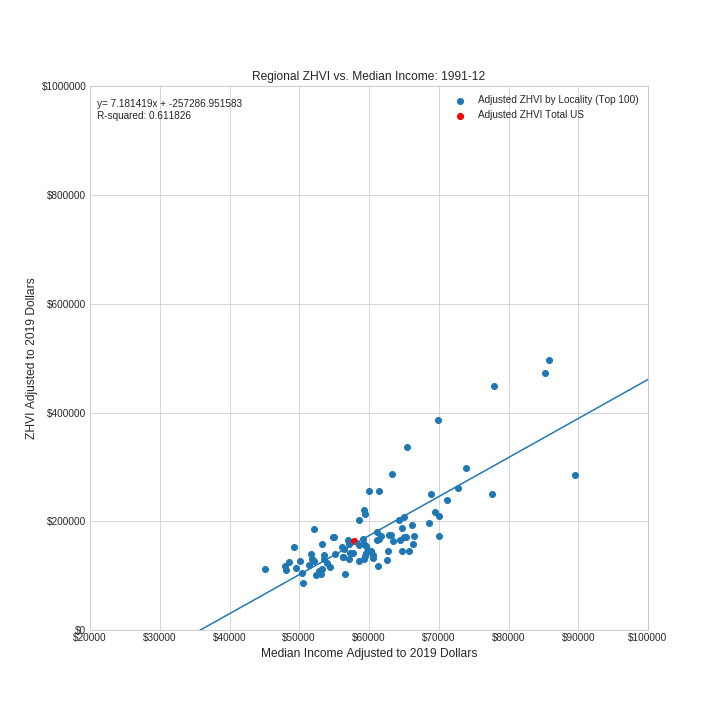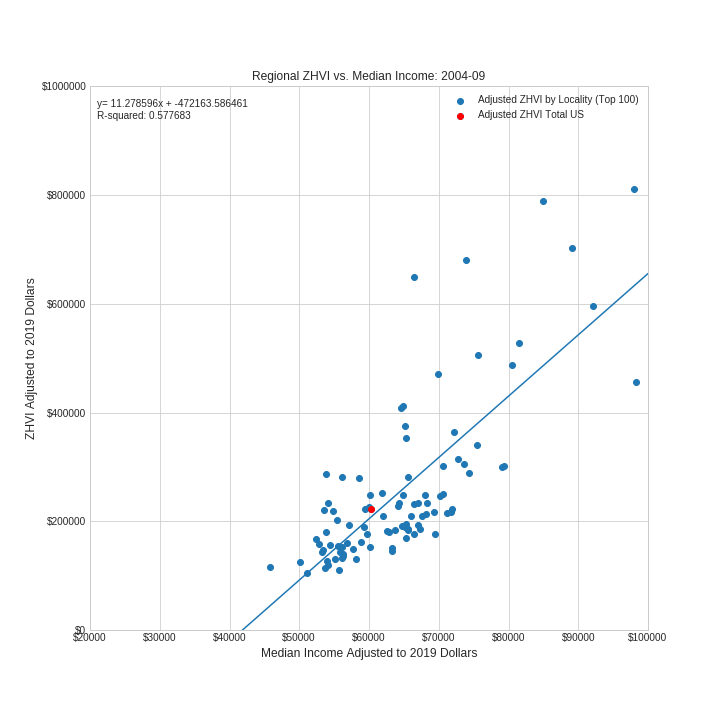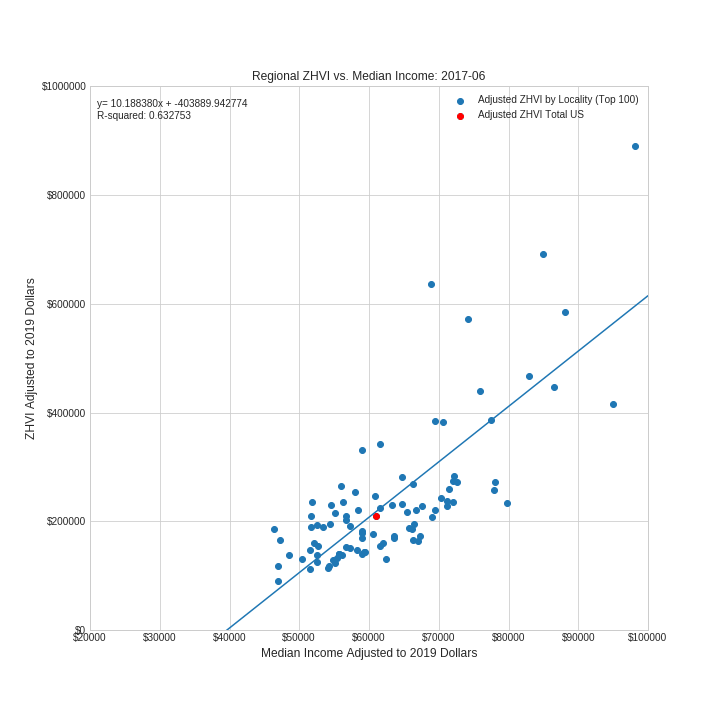
The ZHVI to Median income ratio provides a measure of affordability of the housing market in a given region. The higher the ZHVI to median income ratio the more expensive the region is for its median earner. Therefore, the time-lapse scatter plot gives a good sense of how housing affordability has shifted over time from 1979 to 2017. As can be seen from the increased slope of the regression line, in general it is more expensive to live in higher income areas in 2017 than it was in 1979. Further, just prior to the bursting of the subprime mortgage bubble in 2007 housing prices relative to median incomes were at all time highs for many regions within US.
Imports
import numpy as np
import pandas as pd
import imageio
import datetime
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
Read Data
ZHVI : dataframe containing monthly Zillow Housing Value Index (ZHVI) by region spanning from 1979-03 to 2017-06. ZHVI is a metric of home values created by Zillow. In a nutshell, it is the median of all estimated home values for a given region by month. Data was downloaded from Zillow.
ZHVI = pd.read_csv("../input/median-housing-price-us/Affordability_ChainedZHVI_2017Q2.csv")
ZHVI.head()
| RegionID | RegionName | SizeRank | 1979-03 | 1979-06 | 1979-09 | 1979-12 | 1980-03 | 1980-06 | 1980-09 | ... | 2015-03 | 2015-06 | 2015-09 | 2015-12 | 2016-03 | 2016-06 | 2016-09 | 2016-12 | 2017-03 | 2017-06 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 102001 | United States | 0 | 47420.325963 | 48967.092287 | 50031.142946 | 50986.193294 | 51904.910205 | 52704.245822 | 54225.059691 | ... | 174100.0 | 176600.0 | 179500.0 | 181600.0 | 183800.0 | 186600.0 | 190300.0 | 194200.0 | 197200.0 | 200400.0 |
| 1 | 394913 | New York, NY | 1 | 52563.259032 | 54137.586472 | 55438.816295 | 56434.819370 | 58715.987702 | 59792.313605 | 62330.514988 | ... | 368000.0 | 370900.0 | 374800.0 | 379300.0 | 382100.0 | 386600.0 | 396500.0 | 403400.0 | 412600.0 | 422300.0 |
| 2 | 753899 | Los Angeles-Long Beach-Anaheim, CA | 2 | 73394.779918 | 77180.816449 | 80406.587484 | 83785.158199 | 86875.107296 | 90746.032538 | 93632.248727 | ... | 531300.0 | 539500.0 | 549200.0 | 557600.0 | 566500.0 | 574800.0 | 581400.0 | 594500.0 | 602300.0 | 609800.0 |
| 3 | 394463 | Chicago, IL | 3 | 60177.913481 | 61589.446205 | 61680.095096 | 62495.935111 | 62029.740817 | 62884.430356 | 60281.512213 | ... | 188500.0 | 191300.0 | 193000.0 | 194400.0 | 195800.0 | 198400.0 | 201500.0 | 205200.0 | 209300.0 | 211200.0 |
| 4 | 394514 | Dallas-Fort Worth, TX | 4 | 62602.241939 | 65943.236024 | 68777.723717 | 71310.255676 | 73647.977485 | 74660.990269 | 76901.307002 | ... | 162100.0 | 168300.0 | 175200.0 | 180800.0 | 185300.0 | 190900.0 | 197500.0 | 201600.0 | 206000.0 | 211000.0 |
5 rows X 157 columns
Income : dataframe containing median household incomes by region and month for a period spanning from 1979-03 to 2017-06. Data was downloaded from Zillow.
Income = pd.read_csv("../input/median-housing-price-us/Affordability_Income_2017Q2.csv")
Income.head()
| RegionID | RegionName | SizeRank | 1979-03 | 1979-06 | 1979-09 | 1979-12 | 1980-03 | 1980-06 | 1980-09 | ... | 2015-03 | 2015-06 | 2015-09 | 2015-12 | 2016-03 | 2016-06 | 2016-09 | 2016-12 | 2017-03 | 2017-06 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 102001 | United States | 0 | 16347.78 | 16670.31 | 17005.00 | 17340.92 | 17731.96 | 18018.92 | 18291.96 | ... | 55101.89 | 55571.91 | 55982.59 | 56443.61 | 56781.037105 | 57118.464209 | 57455.891314 | 57793.318418 | 58130.745523 | 58468.172627 |
| 1 | 394913 | New York, NY | 1 | 17537.06 | 17882.32 | 18246.90 | 18628.91 | 19096.50 | 19499.66 | 19871.00 | ... | 68178.78 | 68566.98 | 68916.19 | 69309.90 | 69886.398450 | 70462.896900 | 71039.395351 | 71615.893801 | 72192.392251 | 72768.890701 |
| 2 | 753899 | Los Angeles-Long Beach-Anaheim, CA | 2 | 17915.63 | 18279.35 | 18733.76 | 19230.16 | 19819.58 | 20321.11 | 20702.53 | ... | 61865.99 | 62303.60 | 62759.76 | 63246.79 | 63708.637741 | 64170.485482 | 64632.333224 | 65094.180965 | 65556.028706 | 66017.876447 |
| 3 | 394463 | Chicago, IL | 3 | 20060.12 | 20455.89 | 20900.13 | 21277.76 | 21702.38 | 21852.68 | 21946.23 | ... | 62631.77 | 62890.67 | 63234.29 | 63856.01 | 64306.116564 | 64756.223128 | 65206.329692 | 65656.436256 | 66106.542820 | 66556.649384 |
| 4 | 394514 | Dallas-Fort Worth, TX | 4 | 18151.53 | 18456.96 | 18887.64 | 19463.93 | 20092.82 | 20605.59 | 20967.85 | ... | 61323.91 | 61664.37 | 61856.66 | 61729.10 | 62101.688038 | 62474.276075 | 62846.864113 | 63219.452151 | 63592.040188 | 63964.628226 |
5 rows X 157 columns
CPI : dataframe containing Consumer Price Index (CPI) published monthly for a period spanning from 1960-01 to 2019-07. Data was downloaded from the Federal Reserve Economic Data (FRED). CPI measures changes in the price level of a weighted average market basket of consumer goods and services purchased by households.
CPI = pd.read_csv("../input/consumer-price-index-usa-all-items/USACPIALLMINMEI.csv")
CPI.head()
| DATE | USACPIALLMINMEI | |
|---|---|---|
| 0 | 1960-01-01 | 12.361982 |
| 1 | 1960-02-01 | 12.404174 |
| 2 | 1960-03-01 | 12.404174 |
| 3 | 1960-04-01 | 12.446365 |
| 4 | 1960-05-01 | 12.446365 |
5 rows X 2 columns
Data Preprocessing
The dataframes are melted and merged into a single dataframe. CPI is used to adjust historical income and ZHVI values to the 2019 dollar.
# melt ZHVI to create Date and ZHVI columns
ZHVI = pd.melt( ZHVI, id_vars=['RegionID', 'RegionName', 'SizeRank'], value_name='ZHVI', var_name = 'Date')
# melt Income to create Date and Income columns
Income = pd.melt( Income, id_vars=['RegionID', 'RegionName', 'SizeRank'], value_name='Income', var_name = 'Date')
#merge ZHVI and Income dataframes on ['RegionID','RegionName','SizeRank','Date'] columns
ZHVI = ZHVI.merge(Income, how='outer', on=['RegionID','RegionName','SizeRank','Date'])
#rename CPI columns
CPI.columns = ['Date', 'CPI']
#change CPI Date column values from string to datetime object
CPI.Date = pd.to_datetime(CPI.Date, format="%Y-%m")
#change ZHVI Date column values from string to datetime object
ZHVI.Date = pd.to_datetime(ZHVI.Date, format="%Y-%m")
#merge ZHVI and CPI on Date columns
ZHVI = ZHVI.merge(CPI, how='inner', on=['Date'])
#set CPI index to Date
CPI.set_index('Date', inplace= True)
#calculate average CPI for 2019
base = np.mean(CPI.loc['2019'])[0]
#adjust all income values to the average 2019 dollar value
ZHVI['Income_A'] = ZHVI.Income*base/ZHVI.CPI
#adjust ZHVI values to the average 2019 dollar value
ZHVI['ZHVI_A'] = ZHVI.ZHVI*base/ZHVI.CPI
#set ZHVI index to Date
ZHVI.set_index('Date', inplace = True)
ZHVI.head()
| RegionID | RegionName | SizeRank | ZHVI | Income | CPI | Income_A | ZHVI_A | |
|---|---|---|---|---|---|---|---|---|
| Date | ||||||||
| 1979-03-01 | 102001 | United States | 0 | 47420.325963 | 16347.78 | 29.449364 | 59849.205547 | 173605.763941 |
| 1979-03-01 | 394913 | New York, NY | 1 | 52563.259032 | 17537.06 | 29.449364 | 64203.158387 | 192434.036547 |
| 1979-03-01 | 753899 | Los Angeles-Long Beach-Anaheim, CA | 2 | 73394.779918 | 17915.63 | 29.449364 | 65589.102763 | 268698.212808 |
| 1979-03-01 | 394463 | Chicago, IL | 3 | 60177.913481 | 20060.12 | 29.449364 | 73440.078419 | 220311.278553 |
| 1979-03-01 | 394514 | Dallas-Fort Worth, TX | 4 | 62602.241939 | 18151.53 | 29.449364 | 66452.732417 | 229186.742509 |
Data Visualization
Adjusted ZHVI is plotted against adjusted median income for each quarter from March of 1979 to June of 2017. The US as a whole is plotted in red. A line of best fit is calculated and plotted. Plots are provided to a function which converts them into frames of a gif.
#function to calculate regression line parameters which will be used in resulting plots
def reg(X,y):
regr = LinearRegression()
regr.fit(X,y)
a= regr.coef_
b= regr.intercept_
r= regr.score(X,y)
return a,b, r
#function for creating a plot which will become a single frame of the resulting gif
def plot_gif(date, data):
#create subplot
fig, (ax1) = plt.subplots(nrows =1, ncols =1, figsize=(10, 10), squeeze = True)
#set x to median income by region and y to ZHVI by region fro the given month adjusted to the value of the 2019 dollar
x= data[date]['Income_A']
y= data[date]['ZHVI_A']
#set US_x to median US income and US_y to total US ZHVI for the given month
US_x = data[date].loc[data[date].RegionName == 'United States'].Income_A
US_y = data[date].loc[data[date].RegionName == 'United States'].ZHVI_A
#calculate regression line parameters for x and y
a,b,r = reg(x.values.reshape(-1, 1),y.values.reshape(-1, 1))
a= a.squeeze()
b= b.squeeze()
#set plot style
plt.style.use('seaborn-whitegrid')
#plot x and y
plt.scatter(x,y, label = 'Adjusted ZHVI by Locality (Top 100)')
#plot US_x and US_y in red
plt.scatter(US_x, US_y, c='r', label = 'Adjusted ZHVI Total US')
#set y axis limits
ax1.set_ylim(0,1000000)
#set x axis limits
ax1.set_xlim(20000,100000)
#set axis labels and plot title
ax1.set_ylabel('ZHVI Adjusted to 2019 Dollars', fontsize = 'large')
ax1.set_xlabel('Median Income Adjusted to 2019 Dollars', fontsize = 'large')
ax1.set_title('Regional ZHVI vs. Median Income: '+ date )
#create regression line equation string
reg_equation = 'y= %fx + %f \nR-squared: %f' % (a,b,r)
#annotate plot with regression line equation and r_squared value
plt.text(x= 21000, y=940000,s=reg_equation)
#plot regression line
plt.plot([20000,100000], [a*20000+b, a*100000+b])
#format ticks to include $ sign
formatter =ticker.FormatStrFormatter('$%d')
ax1.yaxis.set_major_formatter(formatter)
ax1.xaxis.set_major_formatter(formatter)
ax1.legend(loc='upper right')
# Used to return the plot as an image array
fig.canvas.draw()
# draw the canvas, cache the renderer
image = np.frombuffer(fig.canvas.tostring_rgb(), dtype='uint8')
image = image.reshape(fig.canvas.get_width_height()[::-1] + (3,))
return image
#limit data to the 100 largest regions within the US
data = ZHVI.loc[ZHVI.SizeRank<100].dropna()
#create gif by passing list of plots and desired fps value into function
imageio.mimsave('./bubble.gif', [plot_gif(date,data) for date in pd.unique(data.index.strftime('%Y-%m'))], fps=20)
Interpretation
The visualization shows the dynamic relationship between home values and median incomes for 100 regions within the US. For any given period this relationship is roughly linear with housing values predictably increasing with increasing median income. However, this relationship is constantly changing. For instance, in March 1979 the slope of the regression line was 2.9 meaning that median home values increased by 2.9 dollars for every dollar increase of median income between regions. In June of 2017 the slope of the regression line was 10.1 a three fold increase in slope. This implies that it is substantially more expensive to live in higher income area in 2017 than it was in 1979. During the height of the housing bubble the slope of the regression line increased to ~ 12. Perhaps the most salient feature of this dynamic plot is the visualization of the boom-bust cylce of the economy which appears as undulating expansions and contractions of the data points over time. For instance, we can visually assess three contractions one in the early 1980s (Early 1980s Recession), one in the early 1990s (Early 1990s Recession) and one in the late 2000s (Financial Crisis of 2007-08). The last of these is especially dramatic, which is not suprising since it corresponds to the bursting of the subprime mortgage bubble.
Another interesting observation is that while some regions change quite a bit over time in terms of median income and home values, other regions are fairly static. For instance, the point (in red) representing the US as a whole, doesn't move substantially from its starting point in 1979 to its end point in 2017.
For those interested, the Ipython notebook and data are dowloadable from Kaggle.